Solr, Episode 1
I learnt a lot of interesting things. This has been a few months, since I started to read about search engine, particularly Solr. I need it because of the requirement at work, but I am really happy to do that. That was fun. So these are what I’ve got so far.
Solr is all about feeding it with data and how you get the data back. When we feed Solr with data, thats called indexing. When we need to get the data back, thats called Query. So two activity that always we do when working with solr is Indexing and Query-ing. If you ever using Database Sql, its like you just do INSERT INTO and SELECT something FROM. Thats simplest explanation.
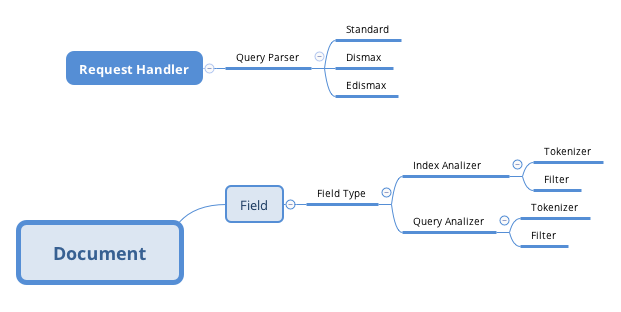
Here is some of term I have to familiar with when working with Solr: Documents, Fields, Field Type, Core, Analyzer, Tokenizer, Filter, Query Parser, etc. Indexing and Query-ing involves some collection of documents, kind of JSON object, in Solr app its called Core. How documents saved and queried, it depends on the field type of fields of the document. Each field type have certain Analyzer. There are two kind of analyzer: Index and Query. Index analyzer, is used when we do the indexing. Query analyzer is used when we do the query.
Each analyzer might be consists of Tokenizer and Filter. Tokenizer and Filter are used to process the text of the documents that we send or fetch. So different with conventional database, Solr saves data what we gave in original form and as another processed form, called index, thats why we called it indexing. CMIIF please.
In regular web app, we use the term ‘Route’ to create web page, or handle web request. In Solr we called it RequestHandler to handle the query we sent (Request). UpdateHandler to handle the data we send, to be saved/indexed. Request Handler is configured in solrconfig.xml in each core conf directory.
Next I might be write about Query Parser and Search Component.